
Here is and amazing and comprehensive hierarchical clustering blog. It will help you in understanding types of clustering algorithms, clustering python, hierarchical clustering dendrogram. It is the widely used types of clustering machine learning and i hope it will he;p you in hierarchical clustering.
Here is a link to see my previous Custering and KMeans Clustering Blog: Clustering Guide: Woking and Application. KMeans Clustering and KMeans++
Clustering
Clustering is a technique used in machine learning and data analysis to group similar objects or data points together based on their inherent characteristics or similarities.
The goal of clustering is to identify patterns, relationships, or structures within a dataset without any predefined labels or categories.
In simpler terms, clustering can be compared to organizing a collection of items into separate groups based on their similarities. Imagine you have a box of various fruits, including apples, oranges, and bananas. To cluster them, you would group the apples together, the oranges together, and the bananas together based on their shared characteristics such as color, shape, or size. Similarly, clustering algorithms aim to identify groups of data points that have similar attributes or properties.
By clustering data, we can gain insights into the underlying structure and patterns within the dataset. This can be useful in various domains such as customer segmentation, image recognition, anomaly detection, and recommendation systems, among others. Clustering allows us to organize and understand complex data by finding groups or clusters of similar data points.
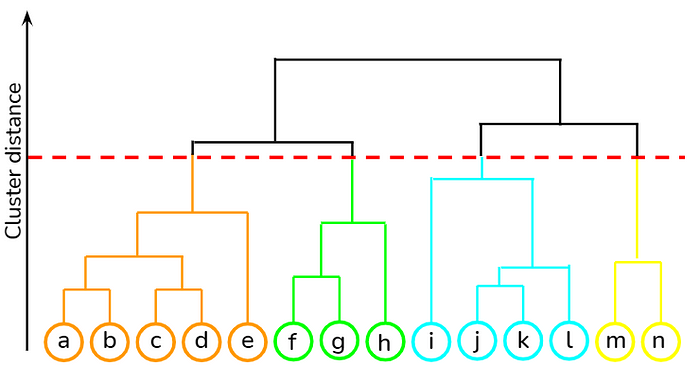
Hierarchical clustering
Hierarchical clustering is a popular clustering algorithm used in data analysis and machine learning. It is a technique that organizes data points into a hierarchy of clusters based on their similarities. In hierarchical clustering, the data points are initially treated as individual clusters and are successively merged together to form larger clusters. This process continues until all data points are part of a single cluster, or until a stopping criterion is met.
Hierarchical clustering can be performed using two main approaches: Agglomerative clustering and Divisive clustering.
Agglomerative Clustering:
Agglomerative clustering starts with each data point as a separate cluster.
At each step, it identifies the two most similar clusters and merges them into a larger cluster.
The similarity between clusters is typically measured using a distance metric such as Euclidean distance or Manhattan distance.
This process continues iteratively, gradually forming a hierarchy of clusters.
The algorithm terminates when all data points belong to a single cluster or when a predetermined number of clusters is reached.
Divisive Clustering:
Divisive clustering takes the opposite approach compared to agglomerative clustering.
It starts with all data points belonging to a single cluster.
At each step, it divides the cluster into two smaller clusters based on some criteria, such as maximizing the inter-cluster dissimilarity or minimizing the intra-cluster dissimilarity.
This process continues recursively, splitting clusters into smaller clusters until each data point is in its own cluster or until a stopping criterion is met.
The result of hierarchical clustering is represented as a dendrogram, which is a tree-like structure that illustrates the sequence of cluster merging or splitting. The dendrogram provides a visual representation of the hierarchy of clusters and allows us to interpret the relationships and similarities between different clusters.
Hierarchical clustering has several advantages. It does not require the number of clusters to be specified in advance, making it a flexible approach. It also captures the inherent structure of the data by forming nested clusters. Additionally, hierarchical clustering can be useful for exploratory data analysis and visualization.
However, hierarchical clustering can be computationally expensive, especially when dealing with large datasets, as the time complexity is generally high. It is also sensitive to noise and outliers, which can affect the clustering results.
Overall, hierarchical clustering is a valuable technique for understanding the structure and relationships within data by forming hierarchical clusters based on similarity measures.
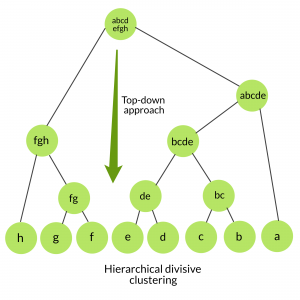
The technique of hierarchical clustering
The technique of hierarchical clustering involves the following steps:
Data Representation: Begin by representing your dataset in a suitable format. Each data point should be represented as a feature vector, where each feature represents a specific attribute or characteristic of the data point.
Distance Calculation: Calculate the similarity or dissimilarity between pairs of data points using a distance metric, such as Euclidean distance or Manhattan distance. The choice of distance metric depends on the nature of the data and the problem domain.
Cluster Initialization: In agglomerative clustering, start by assigning each data point to its own individual cluster. In divisive clustering, start with all data points belonging to a single cluster.
Cluster Similarity Measurement: Calculate the similarity or dissimilarity between clusters. This can be done using various methods, such as single linkage, complete linkage, average linkage, or Ward’s method. These methods determine how the similarity between two clusters is measured based on the distances between their constituent data points.
Merge or Split Clusters: In agglomerative clustering, merge the two most similar clusters based on the chosen similarity measurement. Update the cluster similarity matrix accordingly. In divisive clustering, split a cluster into two smaller clusters based on a suitable criterion, such as maximizing the inter-cluster dissimilarity or minimizing the intra-cluster dissimilarity.
Update Similarity Matrix: Recalculate the similarity between the newly formed clusters and the remaining clusters. Update the cluster similarity matrix accordingly to reflect the changes in cluster relationships.
Repeat Steps 5 and 6: Iteratively repeat the merge or split process until a termination condition is met. This can be when all data points belong to a single cluster or when a predetermined number of clusters is reached.
Dendrogram Construction: Construct a dendrogram to visualize the hierarchy of clusters formed during the clustering process. The dendrogram illustrates the sequence of cluster merging or splitting and provides insights into the relationships between different clusters.
Cluster Extraction: Based on the dendrogram or a predetermined number of clusters, extract the final clusters from the hierarchy. This can be done by cutting the dendrogram at a specific height or by specifying the desired number of clusters.
Cluster Validation and Analysis: Evaluate the quality and coherence of the resulting clusters using appropriate metrics, such as silhouette score or within-cluster sum of squares. Analyze the clusters to gain insights and interpret the underlying structure or patterns in the data.
These steps outline the general technique of hierarchical clustering, which can be implemented using various algorithms and methods. The specific implementation details may vary depending on the chosen algorithm and the software or programming language being used.
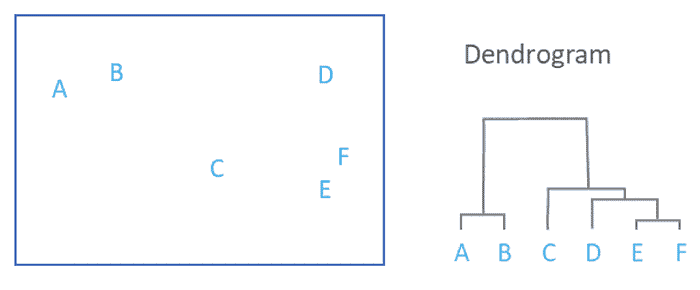
The application of Hierarchical clustering
The application of Hierarchical clustering has a wide range of applications across various domains. Some common applications of hierarchical clustering include:
Customer Segmentation: Hierarchical clustering can be used to segment customers based on their purchasing behavior, preferences, or demographic data. This segmentation can help businesses tailor their marketing strategies and provide personalized recommendations to different customer groups.
Image Segmentation: Hierarchical clustering can be applied to segment images into regions or objects based on their visual similarities. This is useful in image processing, computer vision, and object recognition tasks.
Document Clustering: Hierarchical clustering can group similar documents together based on their content, allowing for topic extraction, information retrieval, and document organization.
Gene Expression Analysis: Hierarchical clustering can be used to analyze gene expression data and identify patterns or clusters of genes with similar expression profiles. This helps in understanding gene functions, and genetic relationships, and identifying potential biomarkers.
Anomaly Detection: By clustering normal or expected data points, hierarchical clustering can help identify anomalies or outliers that do not fit into any cluster. This is useful in fraud detection, network intrusion detection, and outlier detection in various domains.
Recommender Systems: Hierarchical clustering can assist in building recommender systems by grouping similar users or items based on their preferences or behavior. This enables personalized recommendations for users and helps in improving user experience and engagement.
Social Network Analysis: Hierarchical clustering can be applied to analyze social networks and identify communities or groups of individuals with similar social connections or interests. This aids in understanding social structures, influence propagation, and targeted marketing.
Ecology and Species Classification: Hierarchical clustering can help classify and group species based on their ecological characteristics, genetic traits, or geographic distribution. This supports biodiversity studies, conservation efforts, and ecosystem analysis.
Market Segmentation: Hierarchical clustering can be utilized to segment markets based on consumer behavior, demographics, or geographical factors. This assists businesses in identifying target markets, designing marketing campaigns, and optimizing product offerings.
Text Analysis and Natural Language Processing: Hierarchical clustering can be used to cluster documents, text snippets, or words based on their semantic similarities. This aids in text summarization, topic modeling, sentiment analysis, and information retrieval.
These are just a few examples of the diverse applications of hierarchical clustering. Its versatility and ability to reveal inherent structures within data make it a valuable tool in various fields.
Frequently Asked Questions
Q1: What are the advantages of hierarchical clustering?
Hierarchical clustering offers several advantages. It does not require the number of clusters to be predetermined, allowing for flexibility in the analysis. It captures the inherent structure of the data by forming nested clusters. Additionally, hierarchical clustering can be useful for exploratory data analysis and visualization.
Q2: How do you choose the distance metric in hierarchical clustering?
The choice of distance metric in hierarchical clustering depends on the nature of the data and the problem domain. Common distance metrics include Euclidean distance, Manhattan distance, and cosine distance. Euclidean distance is often suitable for numerical data, while cosine distance is used for text or high-dimensional data. The selection of the distance metric should align with the characteristics of the data and the clustering objective.
Q3: Can hierarchical clustering handle large datasets?
Hierarchical clustering can be computationally expensive, especially for large datasets, as the time complexity is generally high. The algorithm needs to calculate the pairwise distances between data points, which can be time-consuming. For large datasets, it may be necessary to use approximations, dimensionality reduction techniques, or parallel computing to improve efficiency.
Q4: How is the similarity between clusters measured in hierarchical clustering?
The similarity between clusters is typically measured using linkage methods. Common linkage methods include single linkage, complete linkage, average linkage, and Ward’s method. Single linkage measures the similarity between the closest pair of data points from different clusters. Complete linkage measures the similarity between the farthest pair of data points. Average linkage calculates the average similarity between all data point pairs from different clusters. Ward’s method minimizes the increase in the within-cluster sum of squares when merging clusters.
Q5: How can I interpret the dendrogram generated in hierarchical clustering?
The dendrogram provides a visual representation of the hierarchy of clusters formed during hierarchical clustering. It shows the sequence of cluster merging or splitting. The height at which clusters merge or split on the dendrogram represents the dissimilarity between them. Horizontal lines in the dendrogram indicate clusters and vertical lines represent the distances at which clusters are merged. By cutting the dendrogram at a specific height or specifying the desired number of clusters, you can extract the final clusters from the hierarchy.
Q6: How can I determine the optimal number of clusters in hierarchical clustering?
Determining the optimal number of clusters in hierarchical clustering can be subjective. One approach is to analyze the dendrogram and identify significant jumps in the vertical distances between merged clusters. These jumps indicate potential cluster boundaries. Additionally, you can use quantitative metrics such as silhouette score or within-cluster sum of squares to assess the quality of clustering for different numbers of clusters. Experimenting with different numbers of clusters and evaluating the clustering results can help in determining an appropriate number of clusters based on the specific problem and domain knowledge.
I hope these questions and answers provide you with a better understanding of hierarchical clustering!
Conclusion
In conclusion, hierarchical clustering is a powerful technique for grouping similar data points or objects based on their inherent similarities. It offers several advantages, including the ability to capture the hierarchical structure of data and the flexibility of not requiring a predetermined number of clusters. Hierarchical clustering is widely applicable across domains such as customer segmentation, image segmentation, gene expression analysis, anomaly detection, recommender systems, social network analysis, and more. By visualizing the clustering results through dendrograms, hierarchical clustering provides insights into the relationships and patterns within the data. However, it should be noted that hierarchical clustering can be computationally expensive for large datasets and is sensitive to noise and outliers. Overall, hierarchical clustering serves as a valuable tool for understanding data structures, identifying meaningful groups, and enabling data-driven decision-making in a variety of real-world applications.
Make sure to check my KMenas Clustering Blog: https://guidingguide.blogspot.com/2023/07/clusteringguide%20and%20explination.html
Code and References:
Here are the links to the official documentation of TensorFlow and scikit-learn, where you can find code examples and explanations of hierarchical clustering using these libraries:
TensorFlow:
TensorFlow Documentation: Hierarchical Clustering (Agglomerative Clustering)
Link: https://www.tensorflow.org/api_docs/python/tf/cluster/hierarchical/HierarchicalClustering
TensorFlow Addons: Hierarchical Clustering (Agglomerative Clustering)
Link: https://www.tensorflow.org/addons/api_docs/python/tfa/clustering/hierarchical
scikit-learn:
scikit-learn Documentation: Hierarchical Clustering
Link: https://scikit-learn.org/stable/modules/clustering.html#hierarchical-clustering
scikit-learn API Reference: Agglomerative Clustering
Link: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.AgglomerativeClustering.html
The provided links will take you to the official documentation of the respective libraries, where you can find code examples, usage instructions, and explanations of hierarchical clustering using TensorFlow and sci-kit-learn.






{kind=link}
0 Comments